This summary is based on this blog.
 Why wouldn’t a Mask_RCNN work out of the box? First, theres’ video, so you got temporal info. Second, you may specify any object and ask the model to track it.
Why wouldn’t a Mask_RCNN work out of the box? First, theres’ video, so you got temporal info. Second, you may specify any object and ask the model to track it.
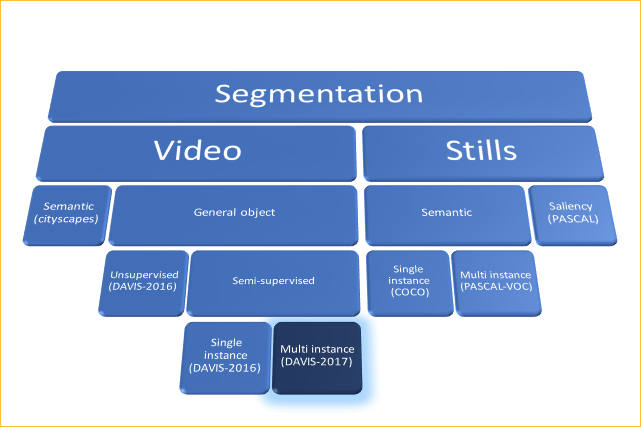
In the video formulation, we can split the problem into two subcategories:
- Unsupervised (aka video saliency detection): The task is to find and segment the main object in the video. This means the algorithm should decide by itself what the “main” object is.
- Semi-supervised: given the ground truth segmentation mask of (only) the first frame as input, segment the annotated object in every consecutive frame.
For the semi-supervised problem, there’re two main apprach: MaskTrack and OSVOS.
One Shot Video Object Segmentation
Maybe oneday it would have its own session, but the core idea (according to blog) is:
- Train a new model for each new video. Base model trained on imageNet, tuned on DADIS-2016.
MaskTrack
- For each frame, feed the predicted mask of the previous frame as additional input to the network: the input is now 4 channels (RGB+previous mask). Initialize this process with the ground truth annotation given for the first frame.
- The net, originally based on DeepLab VGG-16 (but modular), is trained from scratch on a combination of semantic segmentation and image saliency datasets. The input for the previous mask channel is artificially synthesized by small transformations of the ground truth annotation of each still image.
- Add an identical second stream network, based on optical flow input. The model weights are the same as in the RGB stream. Fuse the outputs of both streams by averaging the results.
- Online training: Use the first frame ground truth annotation to synthesize additional, video specific training data.