Just like He’s other works (ResNet etc.), this one’s simple but great. The goal of the paper is to get a self supervised learning learner. This is an approach different than Contrastive learning. State of the Art of course.
Overview
This image kinda gives the overview:
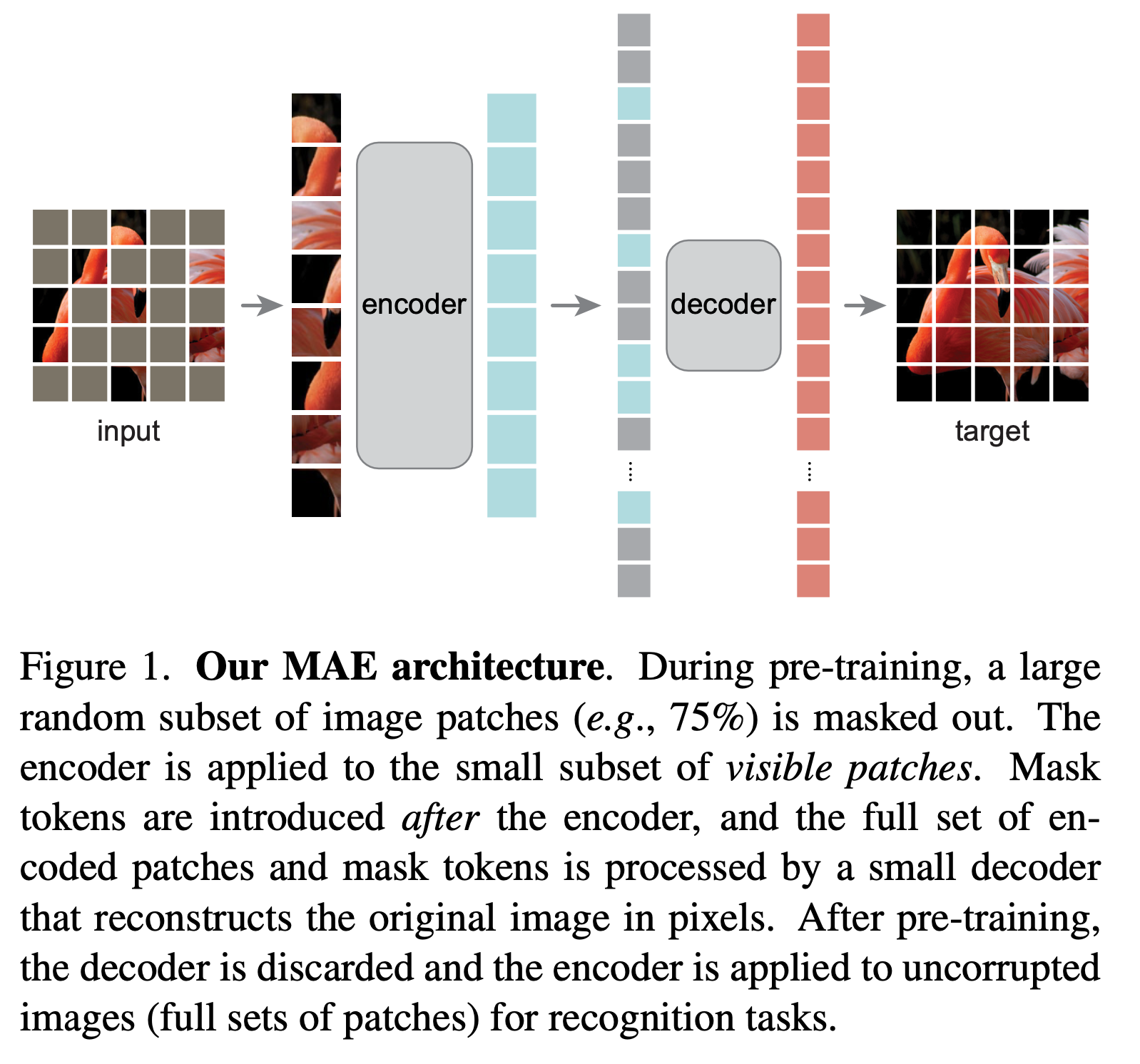
 This souds simple, but here are some novel ideas:
This souds simple, but here are some novel ideas:
- Predicting pixel in image is much simpler than predicting words. So while in BERT we mask out 15%, we get best result at 75% masking.
- We only encode the non-masked pixels. this saves compute, and get better results. That’s because in evaluation / deploy time we never see that mask. So in training time we should not let encoder see it either.
Some details
- The encoder is based on ViT. Linear projection of image patches, with poistional embedding. In this implementation that’s sin / cos embedding.
- The decoder is a simple transformer.
- The loss is only computed on the masked patches
- Mask is a global learnable something
More Studies
- Predicting token adds too much work
- Data augmentation helps, but only a little. That’s because we are already sampling randomly for each input.
- Random sampling is better than block / grid sampling.
How do we eval
Either via end-to-end finetuning, or slap a linar layer on it and just train the last layer (linear probing). In this paper, partial fine-tuning is also explored.