Learning Transferable Visual Models From Natural Language Supervision
Link to the arxiv, Link to the OpenAI blog (more high level), link to the pdf There’s also a blog about zero shot learning, which happenes to use CLIP as the example, which I conder to be even more newbie-friendly than the OpenAI blog.
Core idea: we want zero shot learning, which basically means we don’t need specific label, just pretrain the model with some unstructured data, like Instagram caption, etc. , and then we can just use this no-label model to do some prediction. Pretty amazing. I believe it could be working because that’s a large dataset, and the model is able to extract enough information out of it.
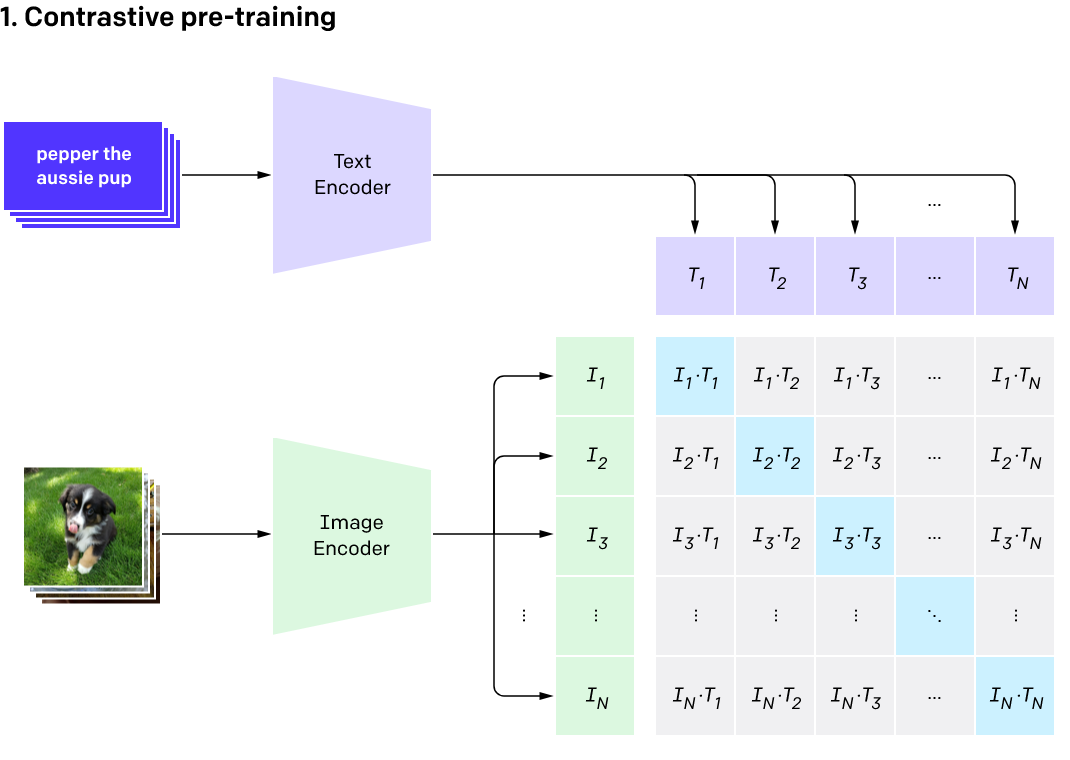
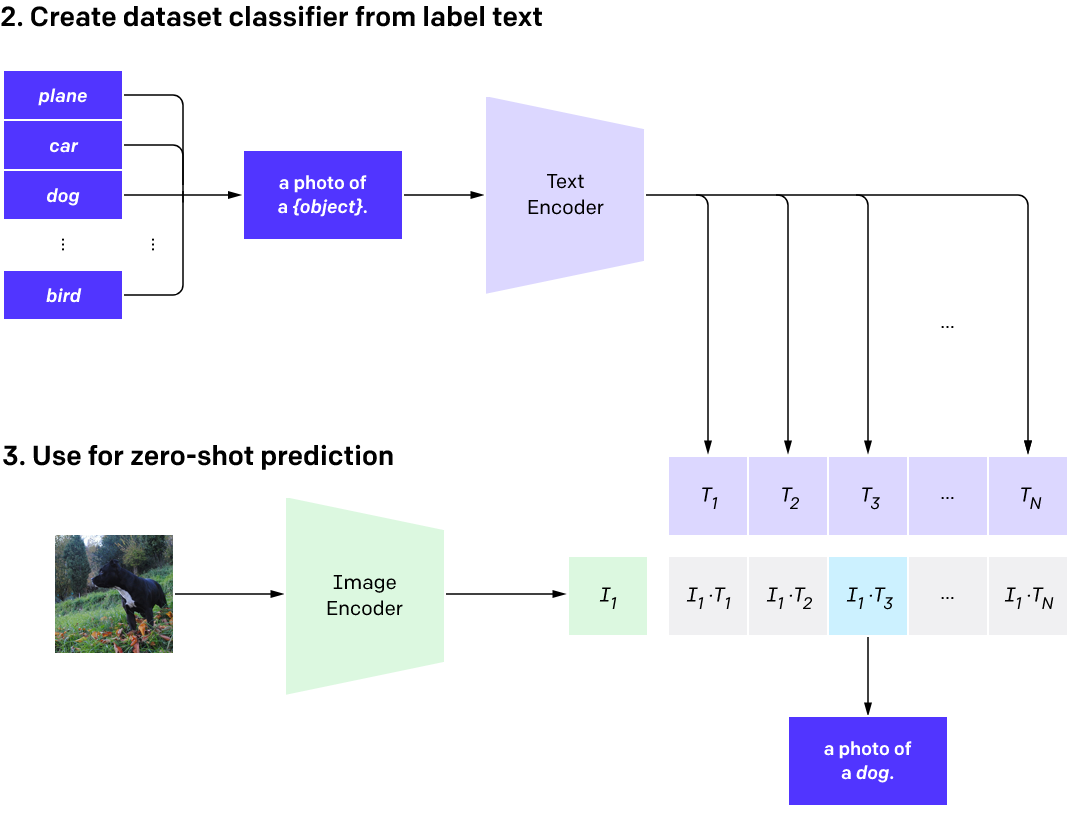
What’s special
Instead of training two models (one image, one text) to try letting them converge on the same embedding, as is used in VirTex (which is a hard task), just try to let the image predict the correct description, say, out of 30k options.
Given a batch of N (image, text) pairs, CLIP is trained to predict which of the N × N possible (image, text) pairings across a batch actually occurred. To do this, CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch while minimizing the cosine similarity of the embeddings of the N 2 − N incorrect pairings. We optimize a symmetric cross entropy loss over these similarity scores.
These guys also create their own dataset as they thought all the existing ones are not enough.
For network structure, they selectively choose some techniques and ignore others for no obvious reason, and adapts something from EfficientNet. Another backbone (and the most performant one) of course is ViT.