MLP-Mixer: An all-MLP Architecture for Vision
Make MLP-only network competitive with CNN and Transformers, even on large scale data.
- It’s not there with SOA CNN-with-attention yet, but close.
- Inference 3 times faster than ViT, similar to CNNs.
- So it seem to prove designed right, MLP could be great, but just on par with best CNN.
Design
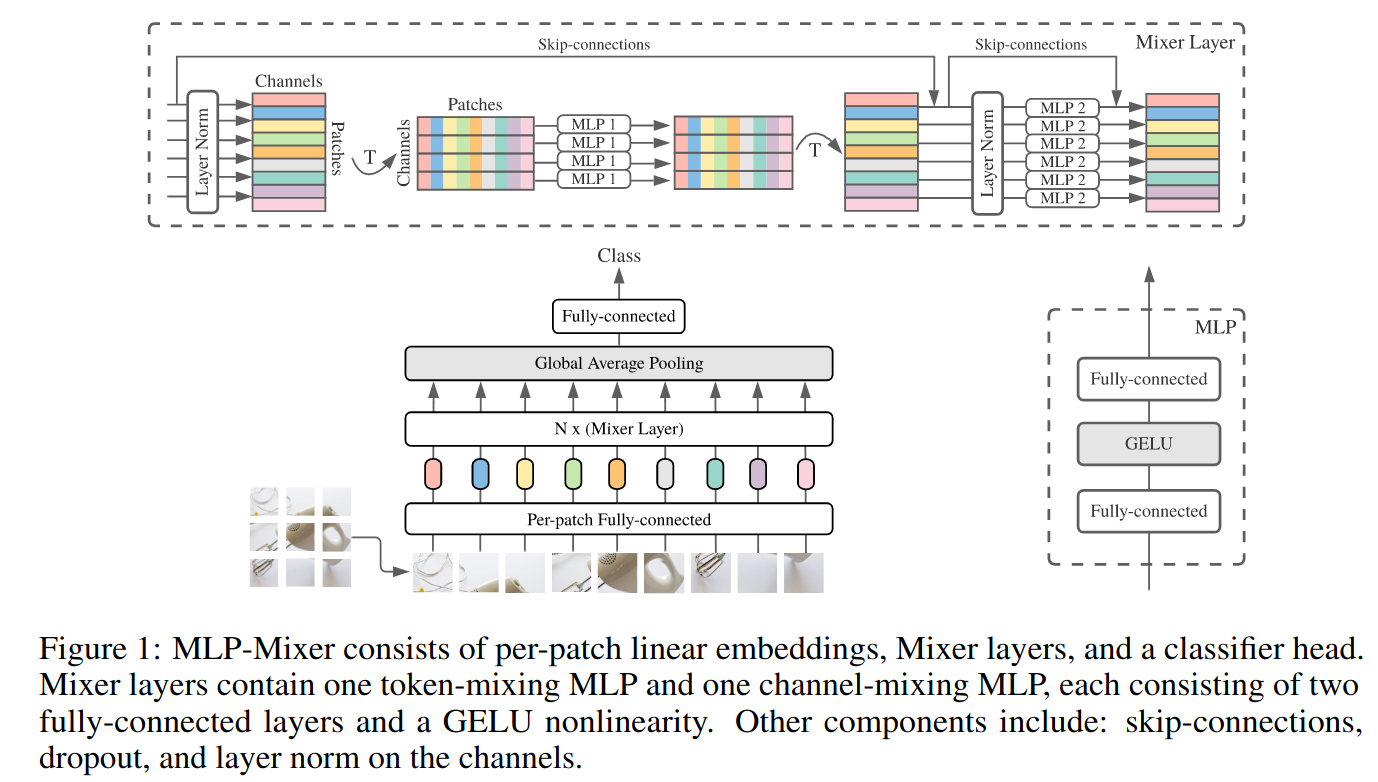
- Divide the image into non-overlapping patches, project to hidden dimension . That’s the colorful bits in the figure.
- Apply Mixer layers, which contains two MLP blocks:
- Token mixing MLP: Mix across different spatial locations (tokens). It mixes channel 1 of all the locations together, 2 together … It can be viewed as a single channel depth-wise convolutions of a full receptive field and parameter sharing. The parameter of this is shared across channels. This is not common, but the result is good so 🤷.
- Channel mixing MLP: Mix within the token. It can be viewed as a convolutions. Again, parameter sharing.
Experiments
- This is easier to overfit so we need extra regularization. But its performance improve fast with the increase of training data.