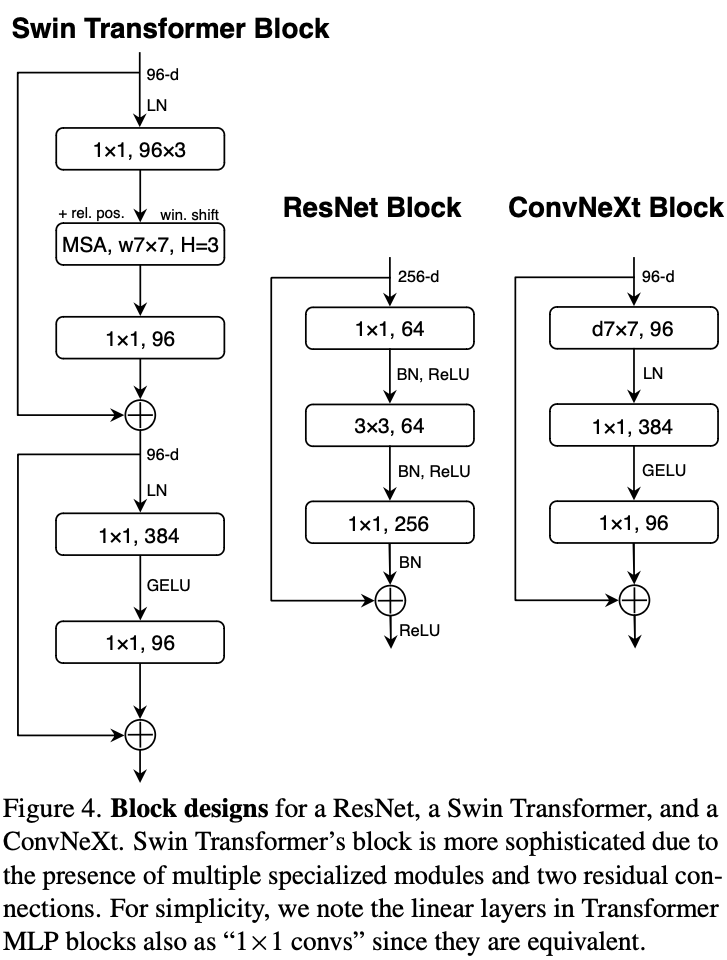
ConvNet for the 2020s
An aggregation of tricks / designs on ResNet so it can outperform Swin Transformer. The authors gradually add in more and more “modernization” pieces.
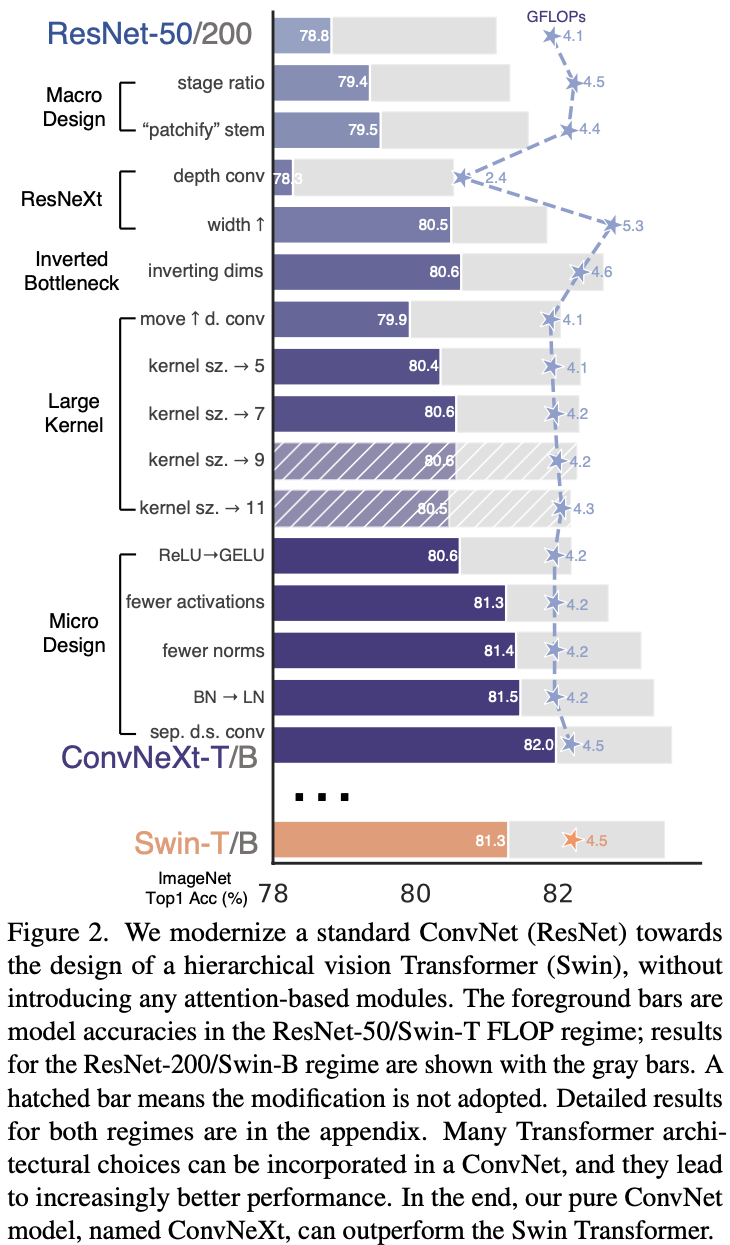
Training techniques
- Close to DeiT and Swin Transformer.
- 300 epochs instead of 90
- AdamW for optimizer
- Augmentation: Mixup, cutmix, RandAugment, RandomErasing
- Regularization: Stochastic Depth, Label Smoothing.
Macro design
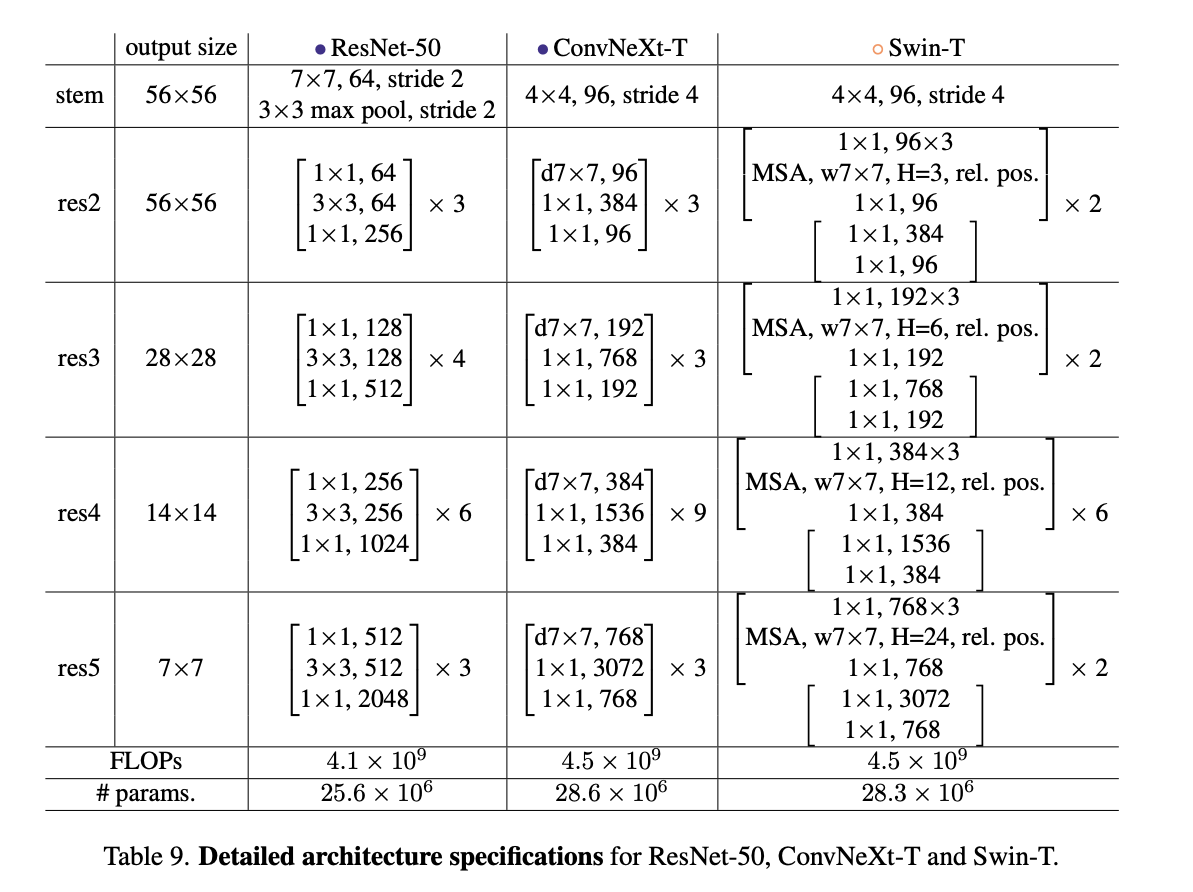
- Stage ratio: Adjust the number of blocks in each stage from to . This is adapted from Swin-T’s similar numbers. It uses , and for larger ones, .
- “patchify stem”: ViT’s style is like kernel size (14 or 16 for a patch) with non-overlapping convolutinon. Swin Transformer’s approach is smaller ones for multi-stage. Here we use a similar approach, stride convolution layer (non-overlapping), for stem which is at the network’s beginning. Comment: We’ll see Large kernel size later. The mentioned here is the how many patches Swin Transformer splits in an image, but each patch is . Plus, the performance doesn’t change much. I don’t think this is something good.
ResNext-ify
- Use ResNext’s idea of grouped convolution. Here we use depthwise convolution, a special case for grouped convolution where the number of groups equals the number of channels. The result is increased FLOPs.
Inverted bottleneck
- Transformers have it. So we’re gonna have this too.(Though it doesn’t bring much performance gain, and make the network runs slower).
- In the following (c), it’s the configuration after we do something afterwards. More random.
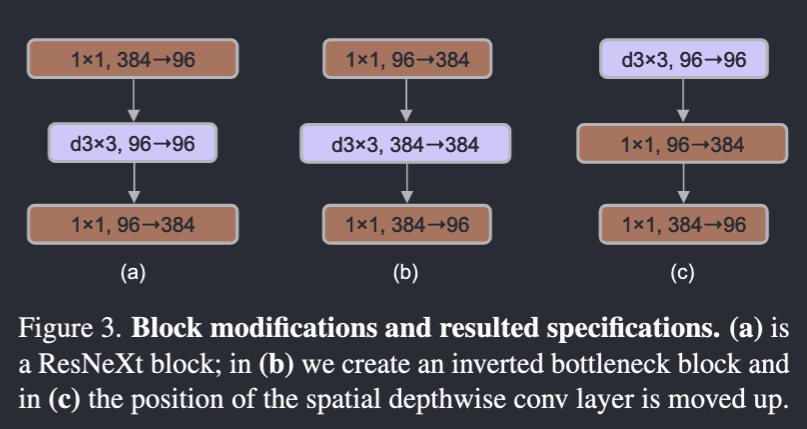 Comment: Another nonsense, only make things slower.
Comment: Another nonsense, only make things slower.
Large kernel size
- So larger kernel size means more computation, so we adapt that (c) above. The authors argue this is also learned from Transformers: self attention layer is prior to MLP.
- And they tried different kernel size, and… is the best. Comment: what a surprise. I mean Swin Transformer is .
Micro design
- Replace RELU with GELU. Exactly the same accuracy.
- Delete GELU in the blocks except for one. Interestingly improves performance. This is suggested by Transformers has fewer activation functions.
- Also delete a BatchNorm layer. Slight improvement.
- Replace BachNorm with LayerNorm. With all the changes previously we got a better performance now.
- Separate out the downsampling layers. Between each stage, conv layers with stride for spatial downsampling. For ResNet it was , at the start of each stage. To stabalize training, some LayerNorm layers are added.