Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This provides a high-performance backbone for a bunch of vision tasks.
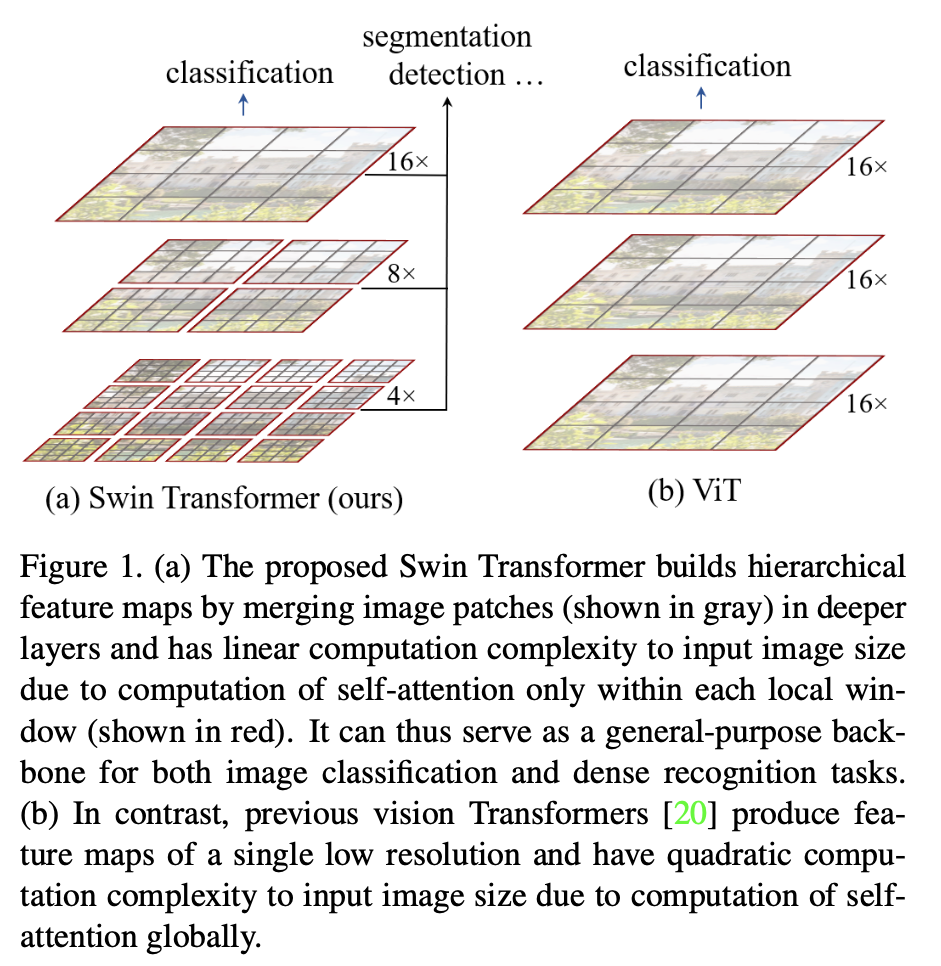
Why ViT is not good enough?
- Its feature map resolution is low. This is unsuitable for tasks like detection / instance segmentation. Recall we just mix everything in a patch in ViT.
- We do self attention across patch, and it’s quadratic increase in compute complexity with image size.
How does this solve the problem?
- Multi-scale feature maps are created. So we can use FPN / U-Net on them.
- We compute self attention locally inside each window. Then we fix the number of patches in each window. As the image size grow, the number of the window grows linearly, thus the complexity also grows linearly, which is good.
So far it’s all summarized in
 !
!
Architecture
Let’s first see the overall picture:
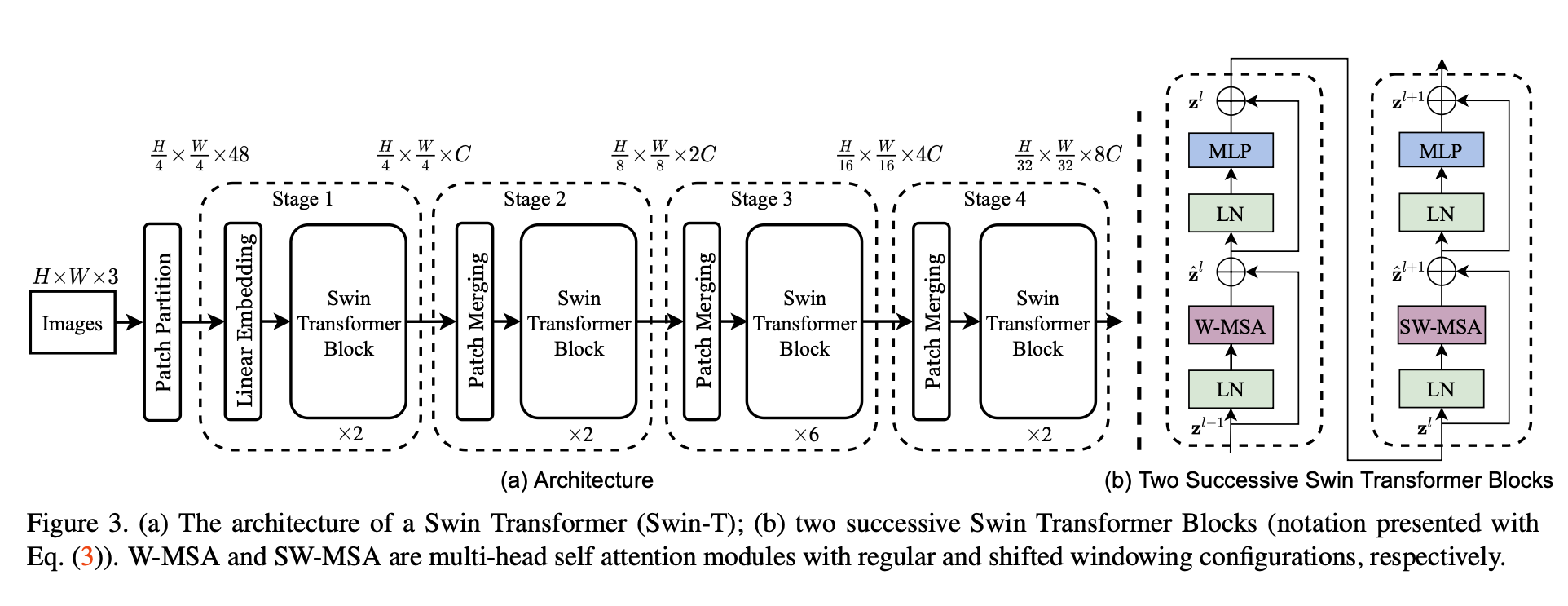 Just like ViT, it:
Just like ViT, it:
- Splits image into non-overlapping patches. In this case , concat raw RGB values, so as feature dimension.
- Apply a linear layer on it to map to dimension.
- Self attention applied within each window. More on that later.
- Do patch merging, basically concats the feature of each group of neighboring patches, and slap a linear layer on it, while doubling the output dimension. So it’s still 2 times reduction on input size for each block.
Now we talk about the shifted window self attention. Just see the figure.
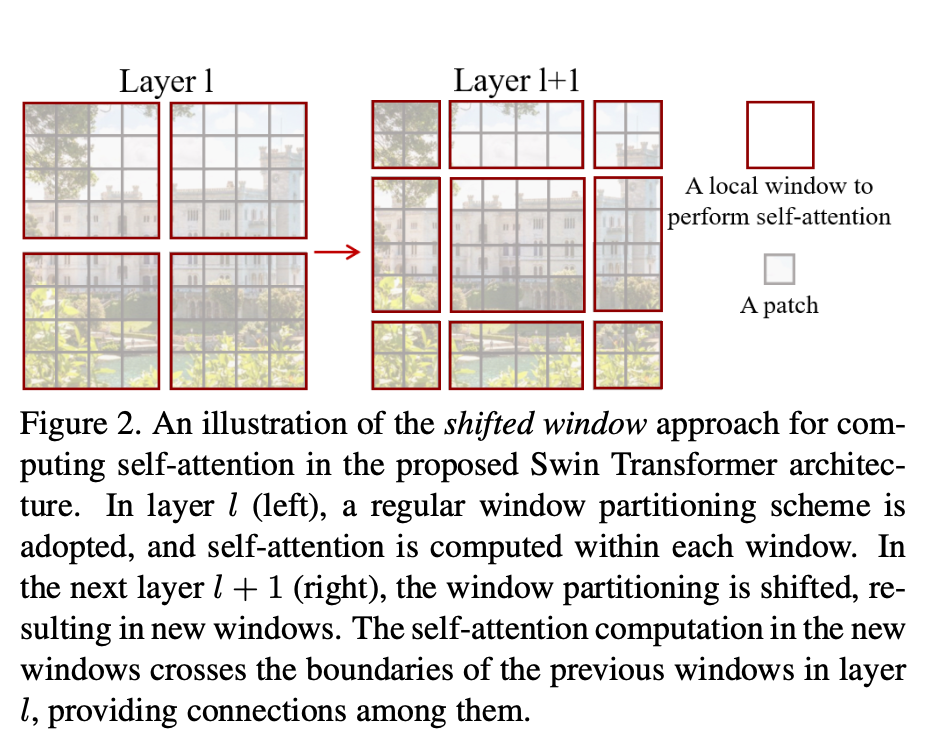
Finally, we may create more window when we shift them, especially if the totally window size is small. we can solve this by moving windows around. Note that we are only creating smaller windows, so we can cleverly mask stuff out in self attention time, and later shift it back.
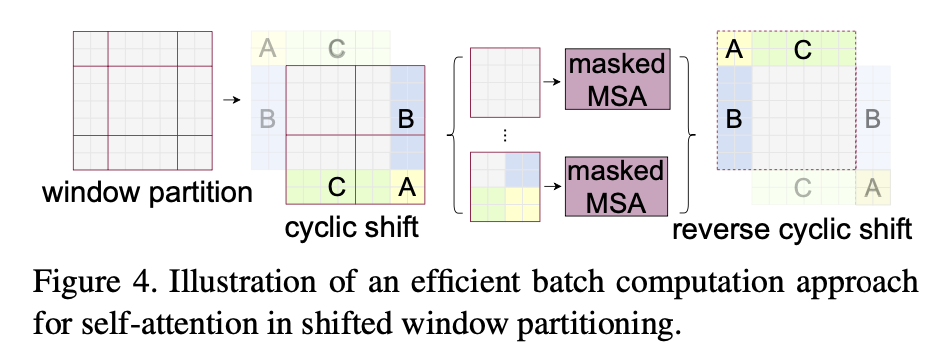
We use window size M = 7 in this paper.