The goal: learn a low level embedding in an unsupervised learning way. E.g. get word embedding.
CCA
CCA is the analog to Principal Component Analysis (PCA) for pairs of matrices. PCA computes the directions of maximum covariance between elements in a single matrix, whereas CCA computes the directions of maximal correlation between a pair of matrices.
So if we got two metrics and , we would like to simultaneously find the directions and that maximize the correlation of the projections of onto with the projections of onto . Writing it in formula:
Here the expectation is assuming and are datasets.
OSCCA (One Step CCA)
TL; DR:
- : vocabulary size
- : the number of tokens in the document. We can represent the document by
- : Left and right context size.
Recall the goal is to find a mapping from dimension to dimension. This is what we call eigenword dictionary. We then have context matrices and , and the tokens themselves, . What’s stored in each row is a one-hot encoding. In , we represent the presence of the word type in the position in a document by setting matrix element .
Create the context as the concatenation . So on each row you got flattened context.
We then can tell the following (not used in the method though):
- contains the counts of how often each word occurs in each context .
- gives the covariance of contexts.
- is the word covariance matrix, a diagonal matrix with the counts of each word on the diagonal. Why? It’s like summation across document.
Then we try to find the projections operated on both context and tokens, such that they have maximal correlation. The projection space we choose has dimension . The intuition is that the context and the token themselves should represent the same thing. There’s a way to compute , see the paper for detalis.
TSCCA
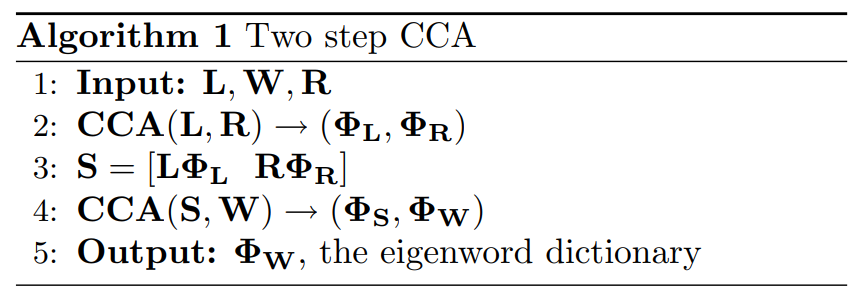
So we first use left and right context to get a state , then do another CCA on .
The two step method requires fewer tokens of data to get the same accuracy in estimating the eigenword dictionary because its final step estimates fewer parameters than the OSCCA does .
Before stating the theorem, we first explain this intuitively. Predicting each word as a function of all other word combinations that can occur in the context is far sparser than predicting low dimensional state from context, and then predicting word from state. Thus, for relatively infrequent words, OSCCA should have significantly lower accuracy than the two step version. Phrased differently, mapping from context to state and then from state to word (TSCCA) gives a more parsimonious model than mapping directly from context to word (OSCCA).