A Simple Baseline for BEV Perception Without LiDAR
The problem it wants to solve: from a bunch of Camera (+ radar) images, get a birds eye view. Note this is different from range image with depth. This also tries to predict stuff like “how long is the truck that I can only see the back”.
TL; DR: For birdeye voxels, get all the image features that might contribute to it, concat the axis, average the images, then slap a CNN on it.
Method
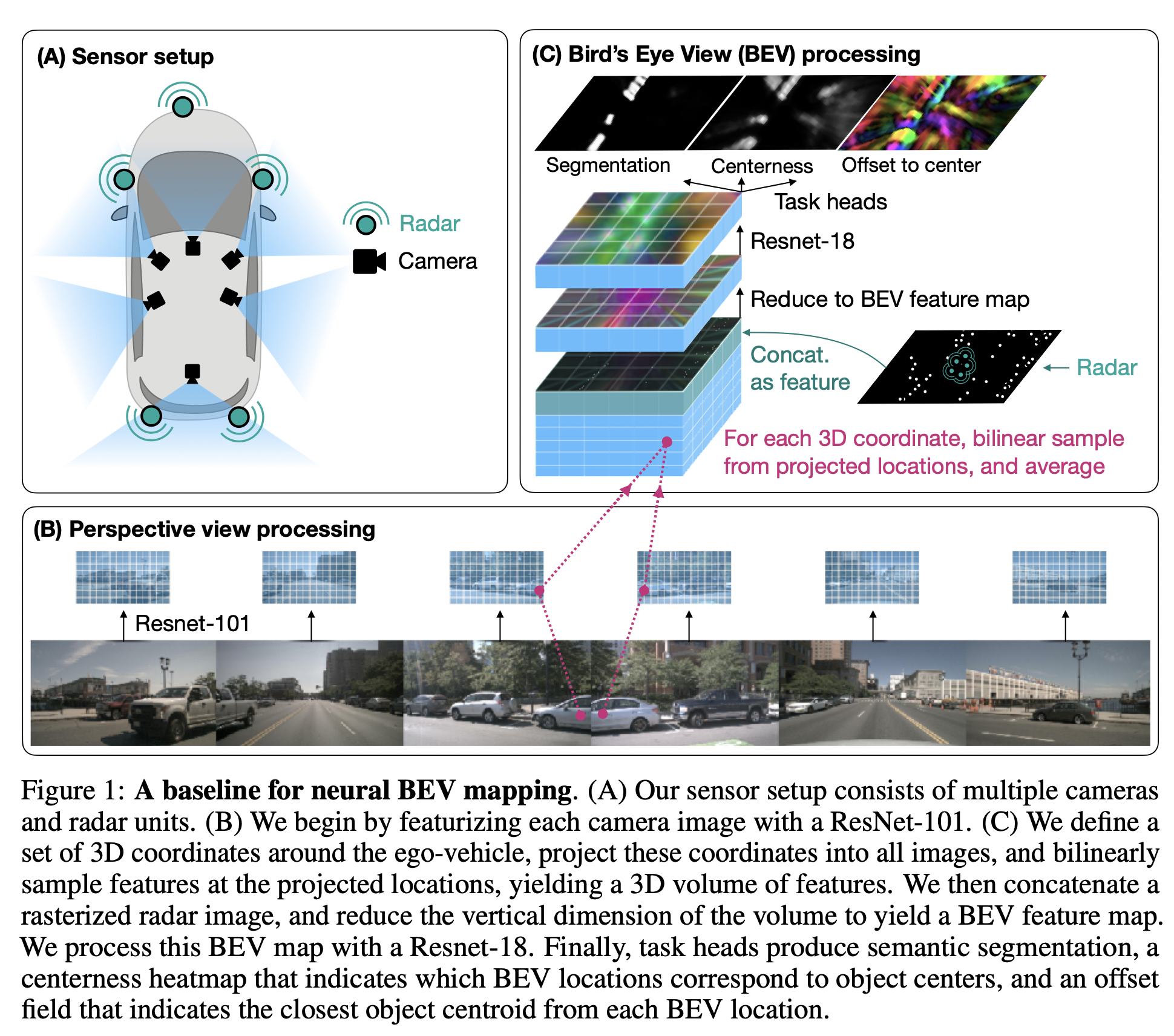
- For every image, go through a pre-trained ResNet to get a 8x smaller feature map. So we got six .
- For the 3D space we want to predict, voxelize it, then project it to feature maps. (3D to 2D). Not sure whether they predict the center of the voxel to get 6 different features.. Then average the images and combine vertical dimention with channel.
- Train three task on it. Use Uncertainty based learnable weighting on them.
- All with instance normalization and ReLu.
Tricks and ablation study
Things gets messy. Some tricks are used by other paper but does not perform well on our model. We think that is because {insert some random reason here}.
- Higher resolution is sometimes better. But too high it’s worse, probably because the pretrained model is not used to that.
- Larger batch size is better.
- Image augmentation or camera drop out is bad. Emm… maybe we want model to overfit. Hmmm