Make One-Shot Video Object Segmentation Efficient Again
A hard-to understand paper that builds on top of OSVOS, with fusion of various technologies.
Video Object Segmentation (VOS) describes the task of segmenting a set of objects in each frame of a video. Why wouldn’t a Mask R-CNN work out of the box? First, theres’ video, so you got temporal info. Second, you may specify any object and ask the model to track it.
Use Mask R-CNN
Instead of using VGG-16 as OSVOS, it direcly fine-tune Mask R-CNN. So a better network plus we already got the mask. Also use Lovász-Softmax loss and group normalization
Meta Learning
OSVOS uses transfer learning. Not good enough. Let’s us Meta Learning. Specifically, follow How to train your MAML, which gives some tricks for training MAML. Learning rate is also learned, on neuron level.
Other stuff
- Bounding Box Propagation. Like Tractor, extend RPN proposals with detected box from previous frame, with random transformations. Note that’s different from MaskTrack, which tries to learn that transformation.
- Online adaption. I don’t know what this means.
Ablation study everyone is waiting for
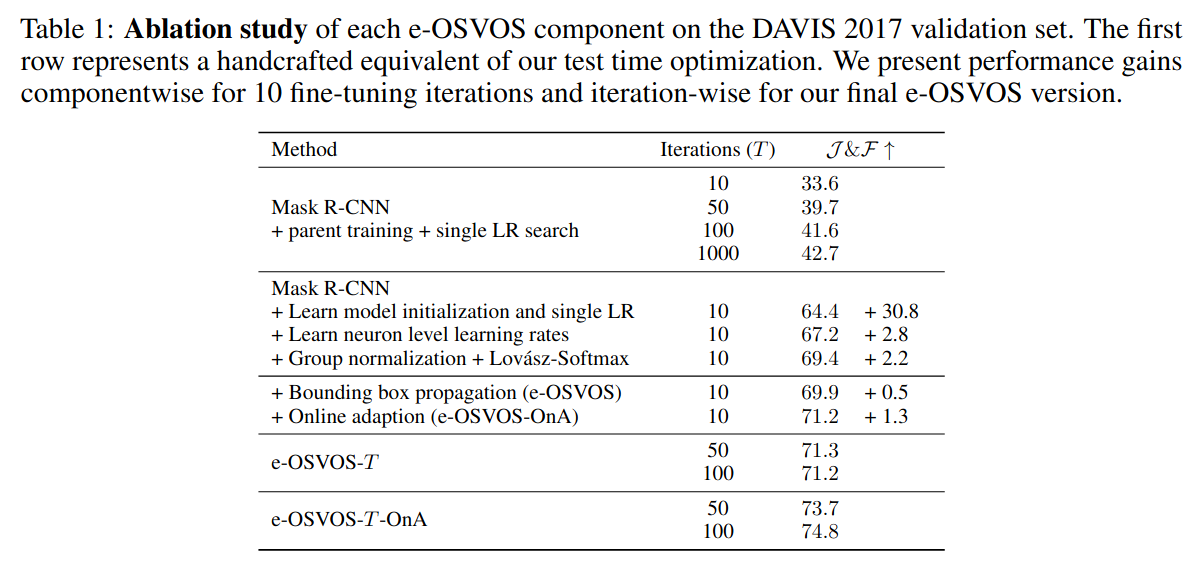 More on eval: it claims it gets a huge boost from meta learning, but the number does not match vanilla OSVOS’s. It’s also not as good as state-of-the-art that time, STM.
More on eval: it claims it gets a huge boost from meta learning, but the number does not match vanilla OSVOS’s. It’s also not as good as state-of-the-art that time, STM.