BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
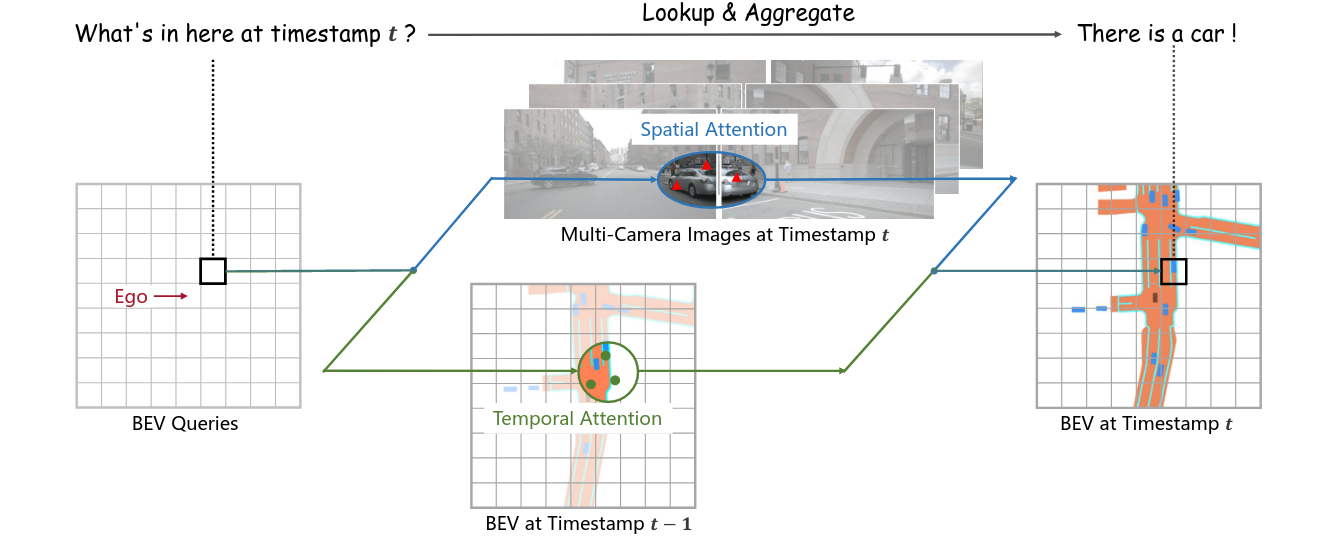
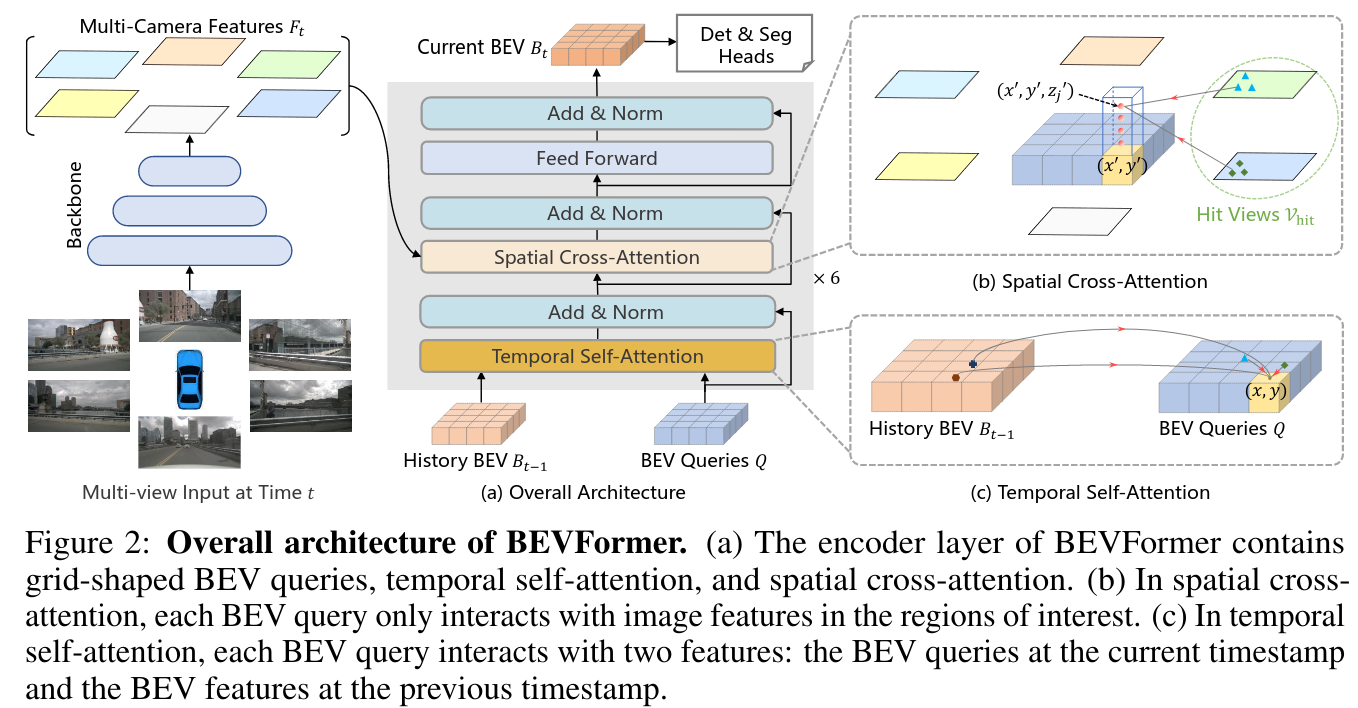
The network’s core representation is in BEV view (BEV query), it uses temporal self attention + spatial cross attention. The author states that they are inspired by Tesla’s video spatial transformer.
BEV Queries
A grid-shaped learnable parameters , each cell correspond to real world geometry.
Spatial Cross-Attetion
This part is like BEV baseline, but it does not just grab context from CNN embedding. Instead, it attend on multiple cameras. It’s not global attention. Instead, it uses Deformable Attention, only interaction with small regions of interest. The reference points are sampled from the lifted pillar.
Basically this means: sum all the things that’s the attention between our BEV query and the image feature around the projected selected points.
Temporal Self-Attention
Align to according to ego-motion, then do self-attention (also deformed) to .
How well does it perform?
Better than other camera-only method that time, but way worse than PointPillars, and even worse than BEV baseline.