Basically this paper is saying “cross entropy loss is not good enough, since it puts too much penalty on good, easy-to-classify examples”. It also provides a “simple” baseline called RetinaNet, which, controversially, isn’t simple at all. The name focal loss doesn’t have anything to do with focal. Just fancy hotness.
Assumptions
- Single stage object detectors are not as good as multi-stage ones because of label class imbalance (mots of the proposed region are negative). Weighing factor kinda fix the issue, but still, it can’t tell easy ones with hard.
Focal Loss
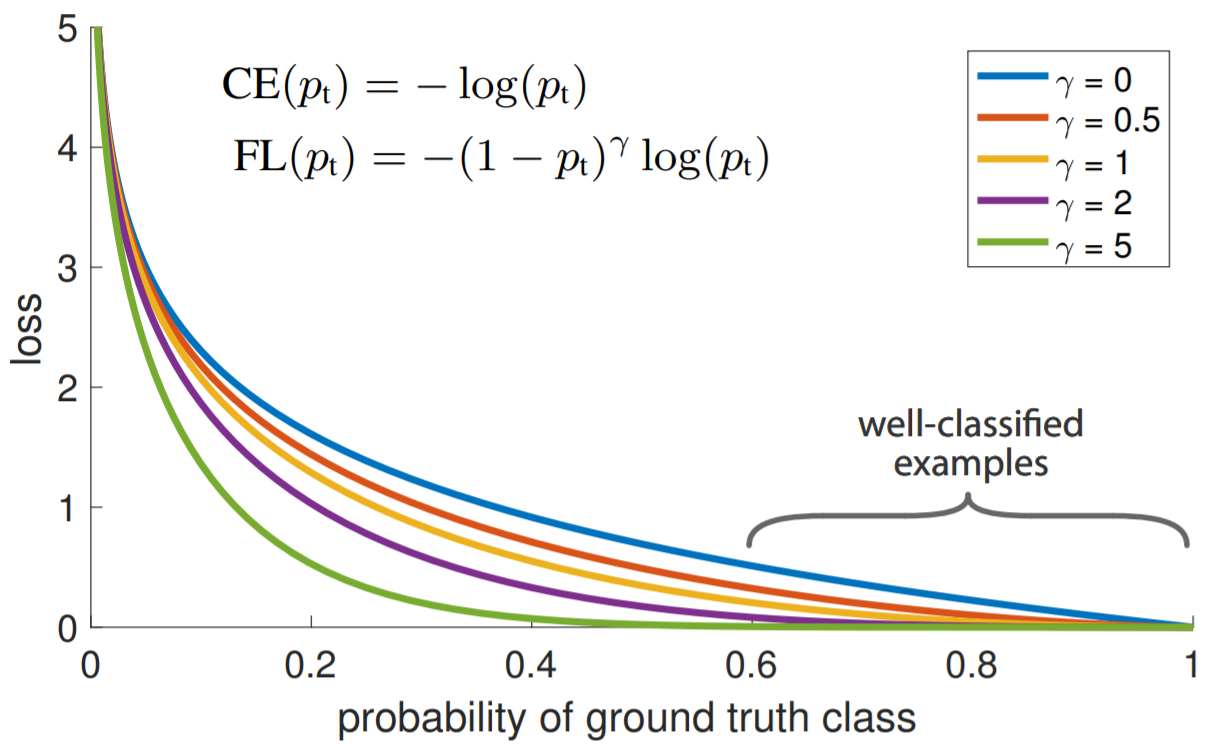 Whether the formula is really this or not is not important. It just need to look like it.
Whether the formula is really this or not is not important. It just need to look like it.
RetinaNet
The network is heavily based on FPN, with tweaks here and there.
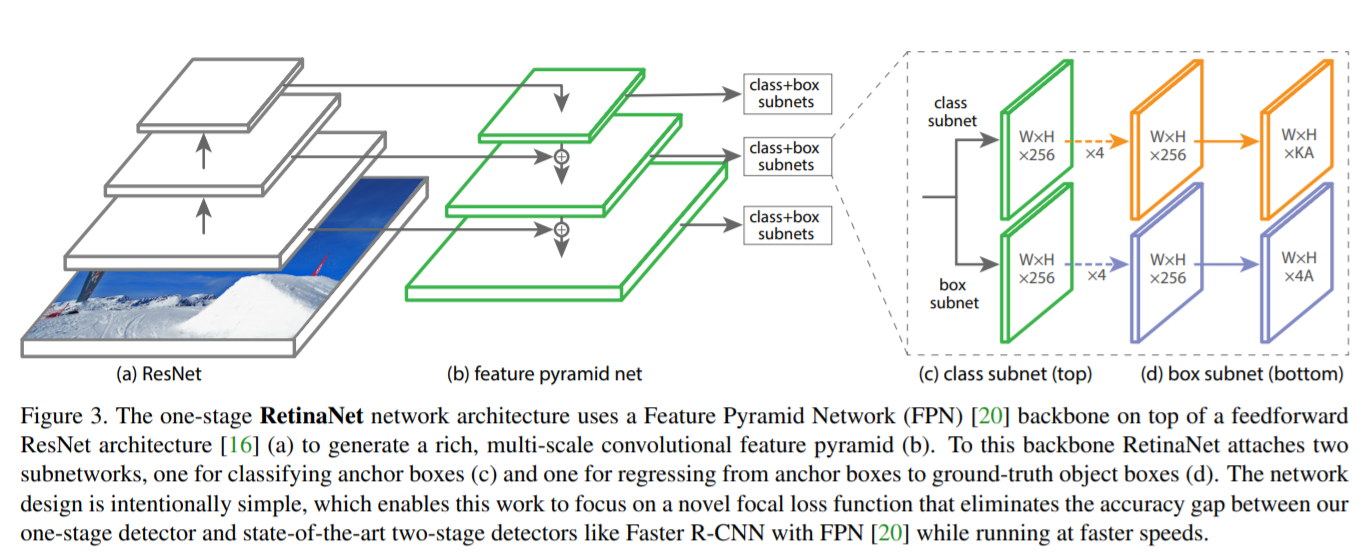 Each convolution here generates an anchor box. And for each anchor, for each possible class, we predict whether it’s foreground / background, and the offset. Well, I said “for each”, but we all know it’s vectorized.
Each convolution here generates an anchor box. And for each anchor, for each possible class, we predict whether it’s foreground / background, and the offset. Well, I said “for each”, but we all know it’s vectorized.
- Tweak the initialization (the Gaussian bias) on the last layer, so that it starts by predicting the object belong to the foreground at a very low probability. If this is not done, the training diverge.
- The author also does grid search on a bunch of other stuff. Like hinge loss, OHEM, etc. I don’t think they are important.