A very very simple adaption of transformer, by dividing image to patches, add class label, add learnable 1d embedding, and go.
Blog link: Transformers for Image Recognition at Scale Paper link
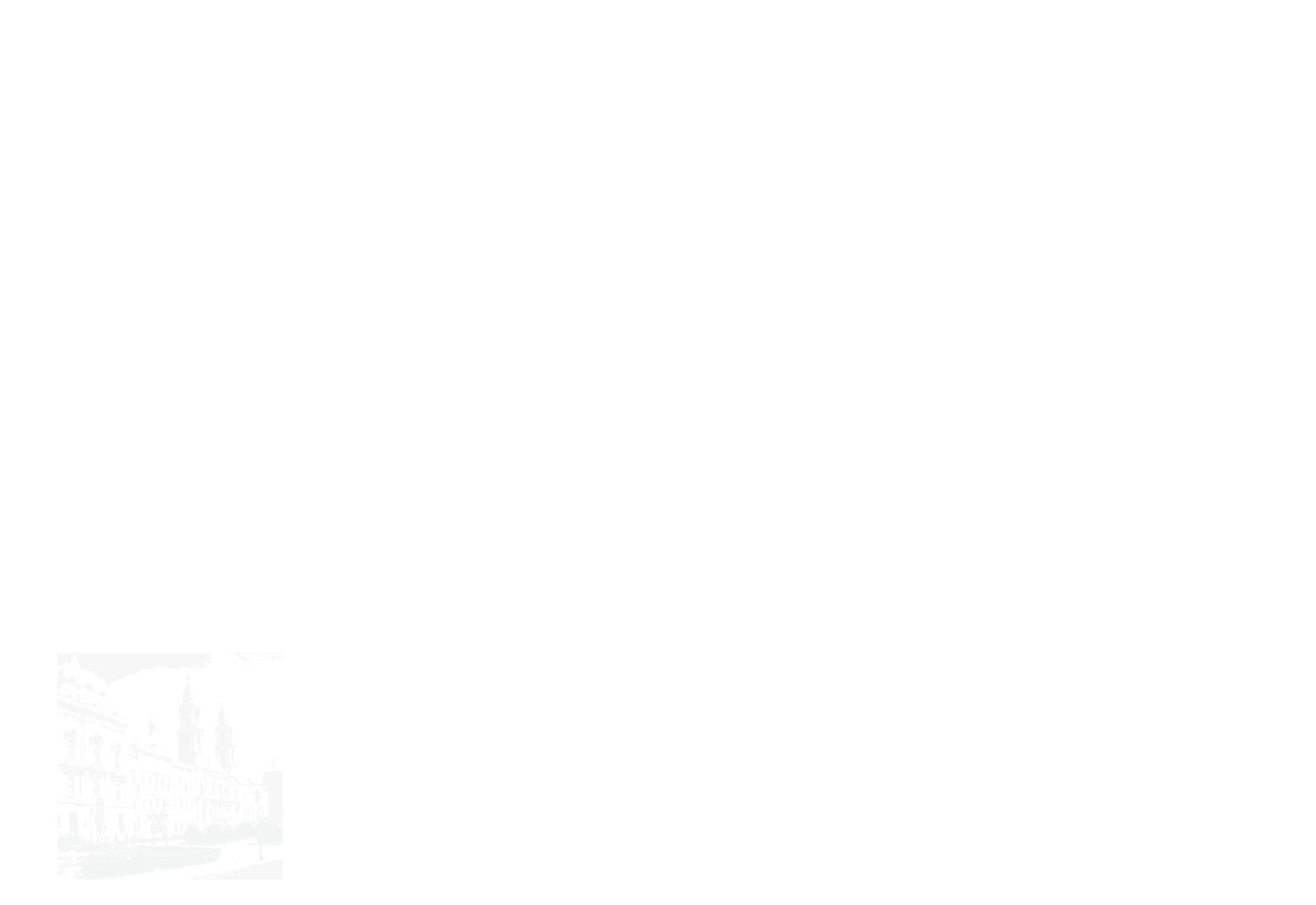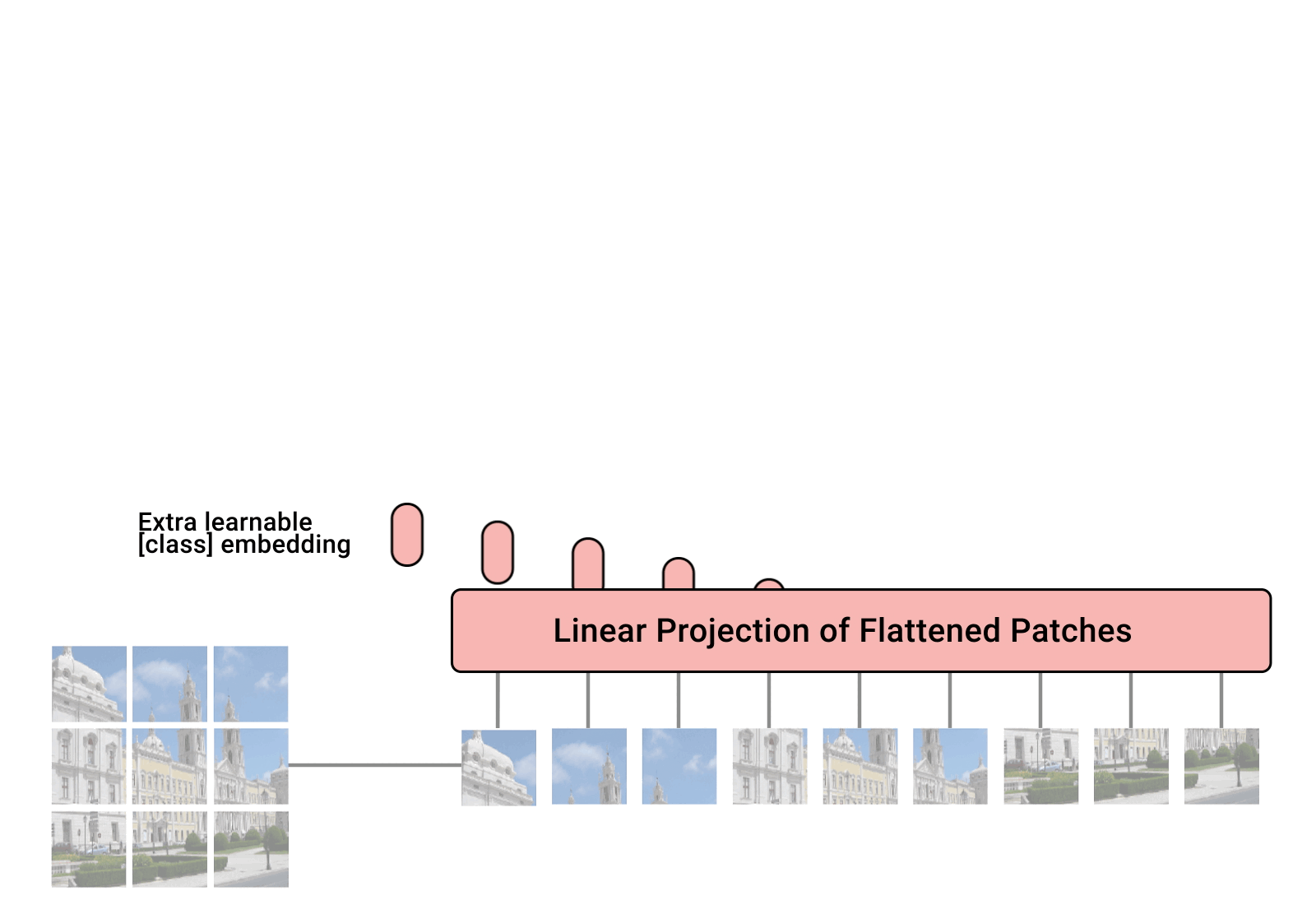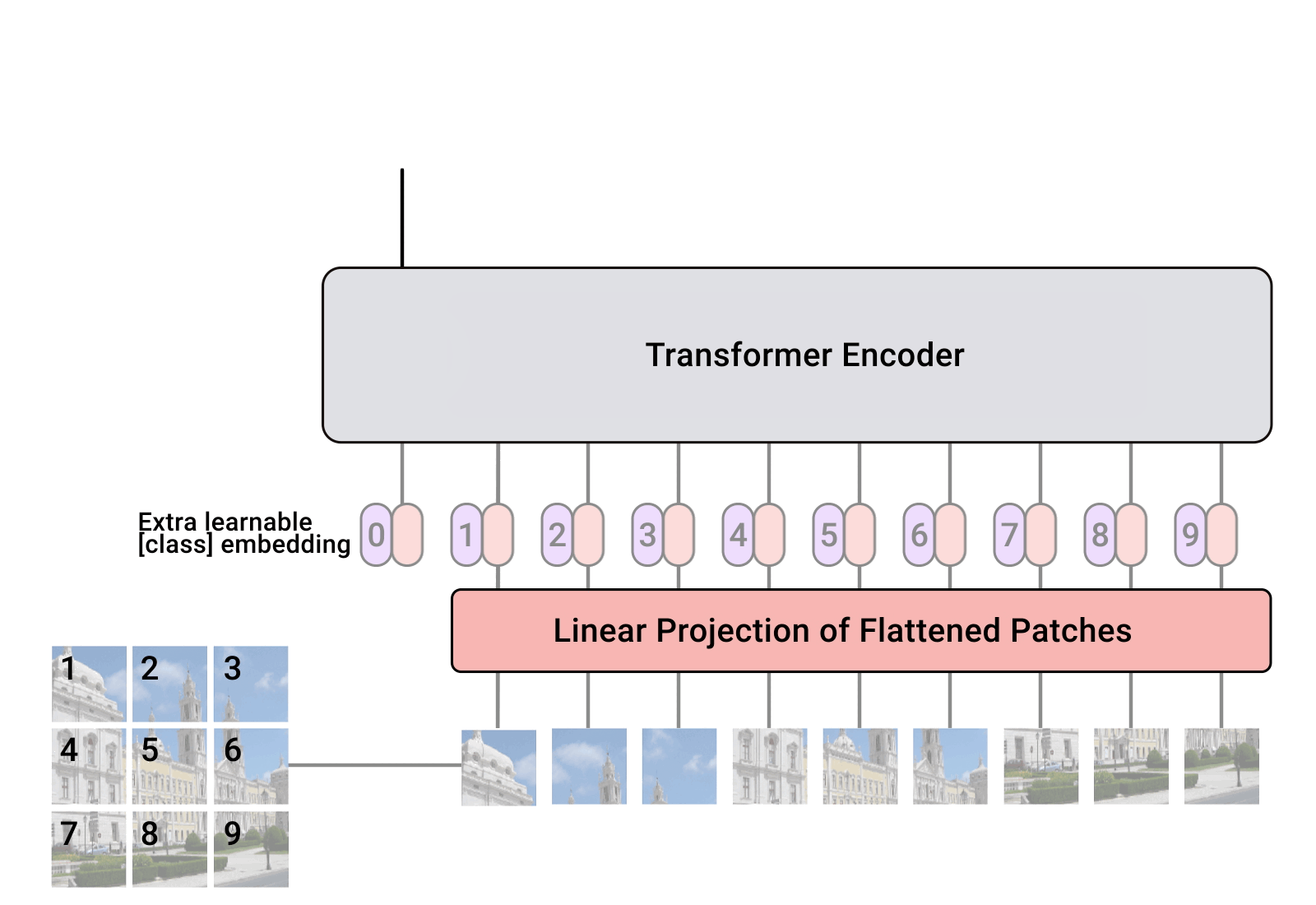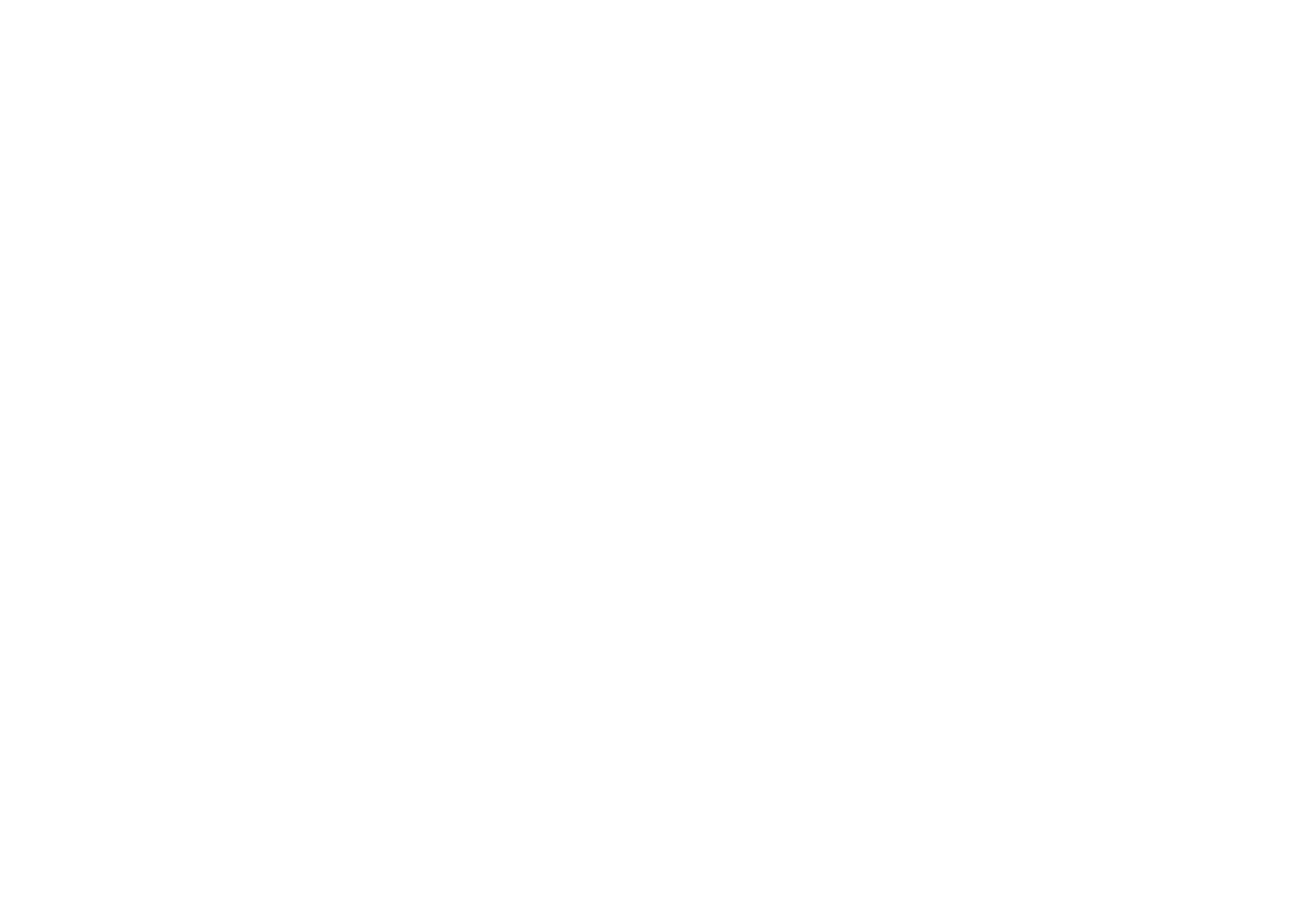
The whole model can be written in 124 lines with PyTorch.
What is the class token here? It’s a random initalized variable that we append to the input, and it’s transformed output is the only thing we care to produce the predicted category. Why don’t we just use a normal FC layer? That’s covered in the Appendix D.3. TL;DR is that we can do that, but we chose not to do that.