End-to-End Object Detection with Transformers
Motivation: a detector without NMS, similar performance as Faster-RCNN, 2 times slower.
Object detection set prediction loss
TL; DR: Hungarian algorithm to make prediction-ground-truth match, and then for each pair we do the normal class prediction and box loss. Represent box by center coordinate, height, width relative to image size.
First step: find a bipartite matching between (ground truth set, ) and ( predictions, ). So we want to find an optimal iterable of index:
This here is care about:
- Does the prediction agree with ground truth class?
- Does the bounding box match?
Second step:
So it’s the spirit of “assuming best intention”, what’s the loss?
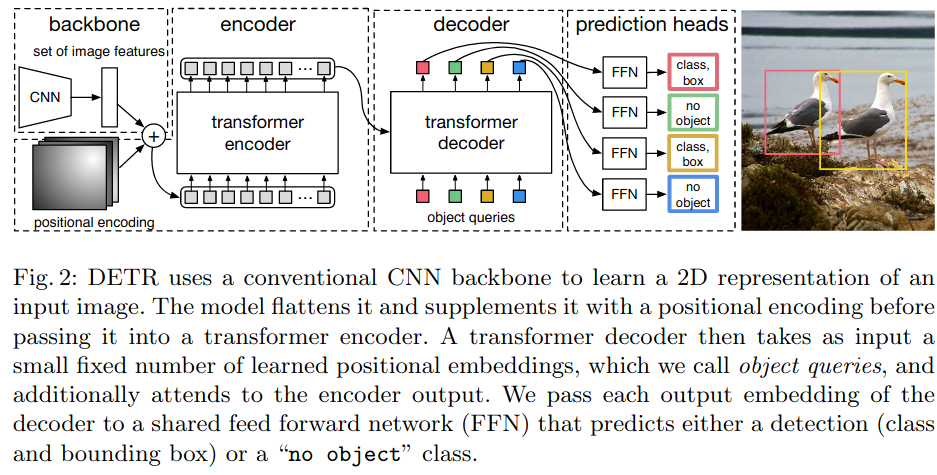
What’s transformers doing here?
Results are generated by providing it with “object queries”, so it produce say, 100 different detections without NMS. It’s discouraged that two detection cover the same ground truth box because of the set loss. It’s different from OG Transformer in that it’s not providing output of this inference run to the next. It’s just giving the object queries.
PyTorch inference code
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads, num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)For clarity it uses learnt positional encodings in the encoder instead of fixed, and positional encodings are added to the input only instead of at each transformer layer. Making these changes requires going beyond PyTorch implementation of transformers, which hampers readability.