A simler method than MAML.
 So basically train several iterations and move the initialization weight accordingly, unlike MAML, not in every iteration.
So basically train several iterations and move the initialization weight accordingly, unlike MAML, not in every iteration.
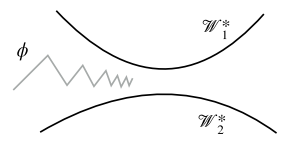
The two black lines represent the sets of optimal weights for two different tasks, while the gray line represents the initialization weights. Reptile tries to get the initialization weights closer and closer to the point where the optimal weights are nearest to each other.
def reptile_sine(model, epochs, lr_inner=0.01, lr_outer=0.001, k=3, batch_size=32):
optimizer = torch.optim.Adam(model.params(), lr=lr_outer)
name_to_param = dict(model.named_params())
for _ in range(epochs):
for i, t in enumerate(random.sample(SINE_TRAIN, len(SINE_TRAIN))):
new_model = SineModel()
new_model.copy(model)
inner_optim = torch.optim.SGD(new_model.params(), lr=lr_inner)
for _ in range(k):
sine_fit1(new_model, t, inner_optim)
for name, param in new_model.named_params():
cur_grad = (name_to_param[name].data - param.data) / k / lr_inner
if name_to_param[name].grad is None:
name_to_param[name].grad = V(torch.zeros(cur_grad.size()))
name_to_param[name].grad.data.add_(cur_grad / batch_size)
if (i + 1) % batch_size == 0:
optimizer.step()
optimizer.zero_grad()